
Identifying Delinquent Loans for Freddie Mac: A Machine Learning Approach
In this project, I developed a machine learning model to predict delinquent loans, aiming to achieve the highest possible recall score. The best performing model was a Logistic Regression model, achieving an average recall score of 0.76.
This model can help Freddie Mac purchase mortgage securities at the correct price, minimizing the negative impact of delinquent loans on the market.
Key Findings:
Data Analysis: I conducted a comprehensive exploratory data analysis, handling null values and identifying key features for the model.
Model Selection: Various models were tested including Logistic Regression, XGB, Random Forest, Voting Classifier, and Stacking.
The Logistic Regression model outperformed others in terms of recall score.Model Interpretation: I used LIME (Local Interpretable Model-Agnostic Explanations) for model interpretation, ensuring the model's decisions can be understood and validated.Compliance with Fair Housing Act:
The interpretability of the Logistic Regression model ensures compliance with the Fair Housing Act, which prohibits discrimination in housing financing.
Future Research:Deep Learning models could be explored to improve precision, although their compliance with the Fair Housing Act needs to be examined.
Freddie Mac was chartered by the US Congress in 1970 with the goal of supporting the US housing finance system and ensuring a reliable and affordable supply of mortgage funds nationwide.
Instead of directly lending to borrowers, Freddie Mac operates in the US secondary mortgage market. They purchase loans that meet their standards from approved lenders.
As a result, these lenders can offer more loans to qualified borrowers and maintain a steady flow of capital into the housing market. Freddie Mac then pools the mortgages it acquires into securities, which are sold to investors globally.
More about Freddie Mac here.
This model could play a crucial role in pricing these risks accurately when purchasing securities, ensuring a fair deal for all parties involved. Maintaining a healthy mortgage market for US citizens who aspire to own property is of utmost importance to Freddie Mac.A recommended industry standard, established by Turiel, J. & Aste, T. (2019), researchers at University College London, sets a recall score benchmark of 77.4%.
Data can be found here: https://www.kaggle.com/datasets/saravananselvamohan/freddie-mac-singlefamily-loanlevel-dataset
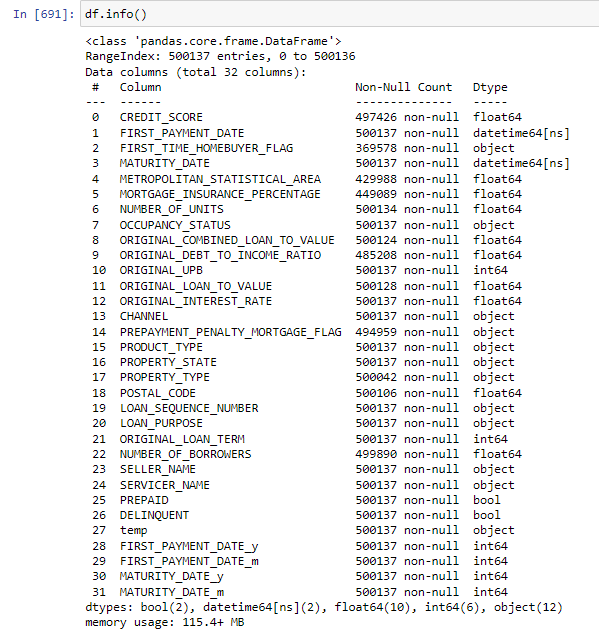
- Plenty of nulls for several columns we will review how to impute each in another section
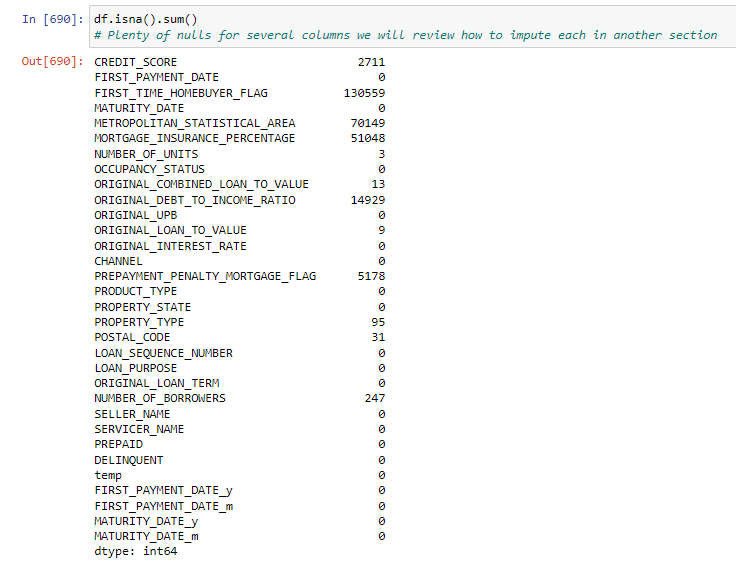
Label
- Highly imbalance data just 3.5% of the total customers are delinquent.
Correlations
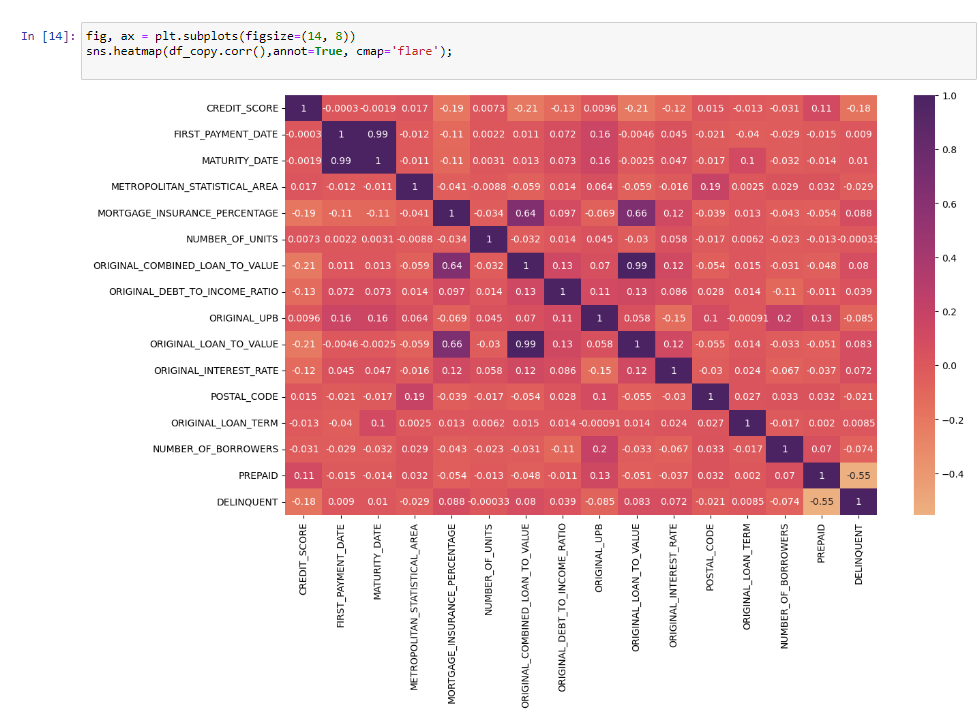
From the previous image we can conclude that the majority of values show no significant correlations except the following:
- First_Payment with Maturity which is logical since they are related dates.
- ORIGINAL COMBINED LOAN-TO-VALUE (CLTV) is calculated from Original Loan to Value that is why the are correlated
- Prepaid should not be part of the Final model as Prepaid means the customer had paid in advance the mortgagen however there are not completely negative correlated, more analysis is needed.
- Strong correlation between Mortgage insurance and Original Loan to Value, which is also a requirement. If customers is requiring a loan closer to 100% of the property the mortgage insurance will also increase.
- Mortgage insurance is typically required when the loan-to-value (LTV) ratio of a home loan is greater than 80%. This means that the borrower is financing more than 80% of the value of the property, which increases the risk for the lender and that is why they are correlated
Creating Functions to clean dates and create month and year columns
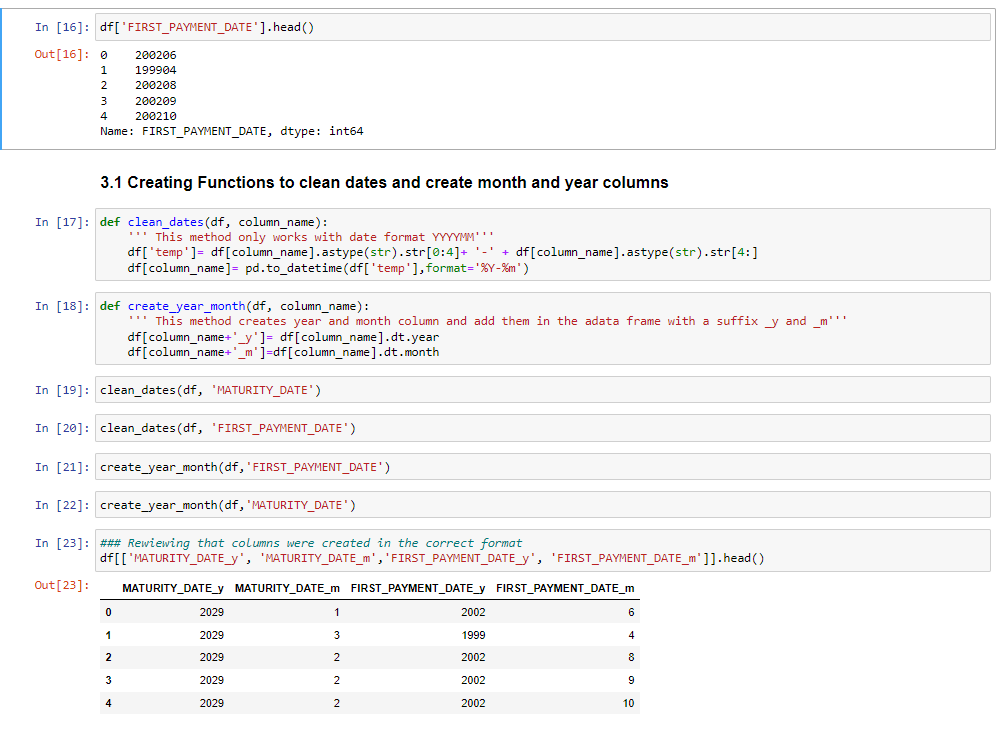
The year when the loan was originated. Data shows predominant values from 1999 to 2002.
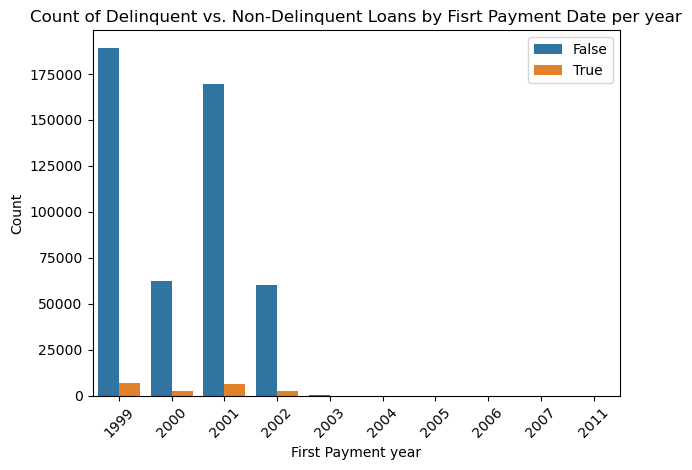
The month when the first payment was done. Data shows predominant values from March to May.
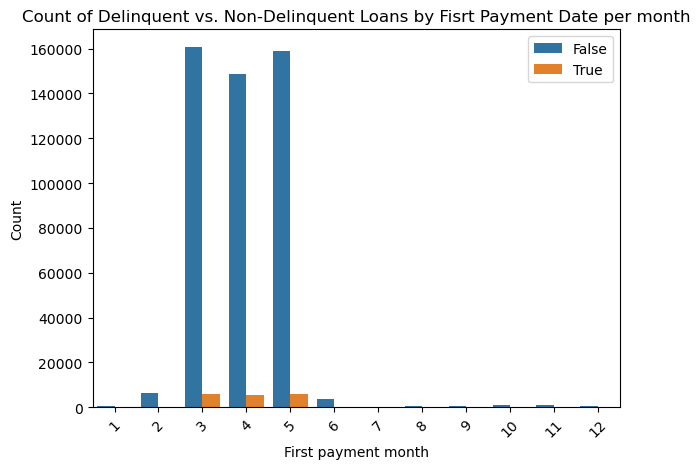
The great majority of loans are 360 months or 30 years, which is true for bot delinquent and not delinquent
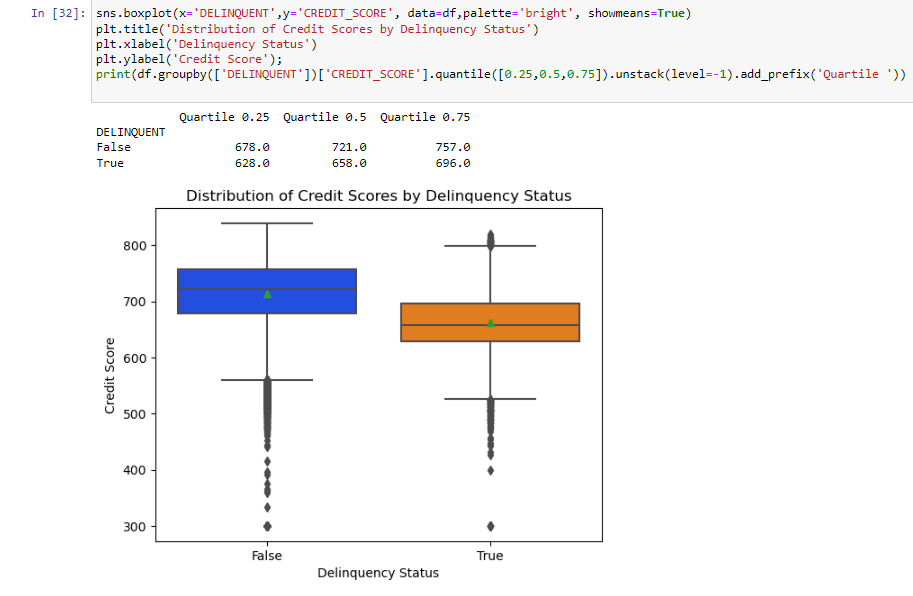
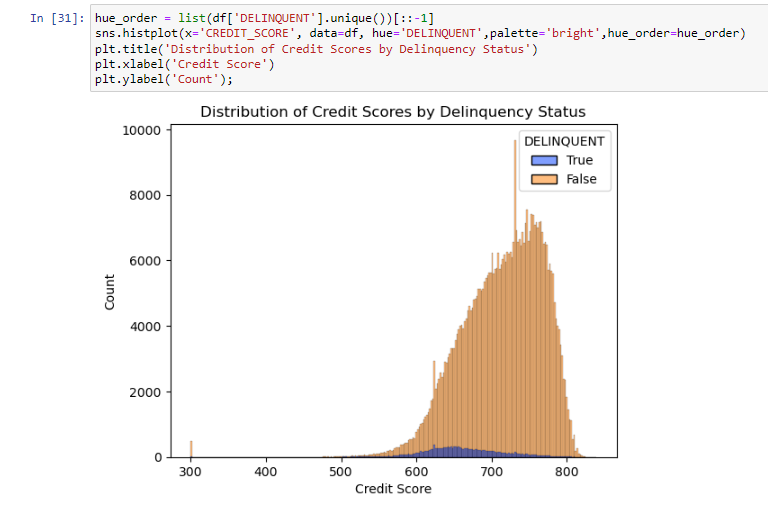
Credit Score
- A number, prepared by third parties, summarizing the borrower’s creditworthiness, which may be indicative of the likelihood that the borrower will timely repay future obligations
- We can clearly see that Delinquent clients had a lower credit score than non-delinquent clients
- Median and Quartiles are lower than non-delinquent customers
ORIGINAL LOAN-TO-VALUE (LTV)
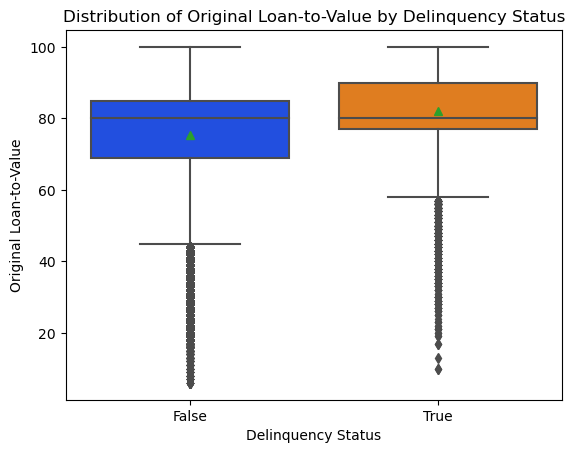
- In the case of a purchase mortgage loan, the ratio obtained by dividing the original mortgage loan amount on the note date by the lesser of the mortgaged property’s appraised value on the note date or its purchase price
- Similar to other variables, the appraisal of the house is closer to 100% for delinquent customers this makes the loan riskier
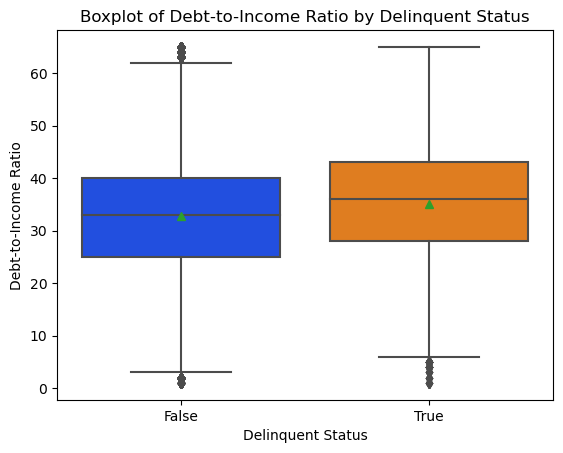
Debt to income ratio
- Disclosure of the debt to income ratio is based on: borrower's monthly debt payments divided by the total monthly income used to underwrite the loan as of the date of the origination of the such loan.
- Similar to combined loand to value the Debt to Income ration are an important metric on how risky is the loan and we can see clearly, Delinquent customers have a higher Debt to income ratio although not by much.
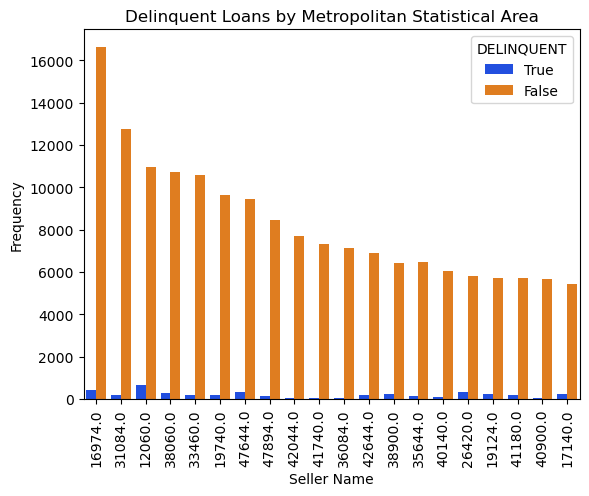
METROPOLITAN STATISTICAL AREA
- Metropolitan Statistical Areas (MSAs) are defined by the United States Office of Management and Budget (OMB) and have at least one urbanized area with a population of 50,000 or more inhabitants.
- The top 20 MSA have different proportion of Delinquent and not delinquent customers which can be useful for the model.
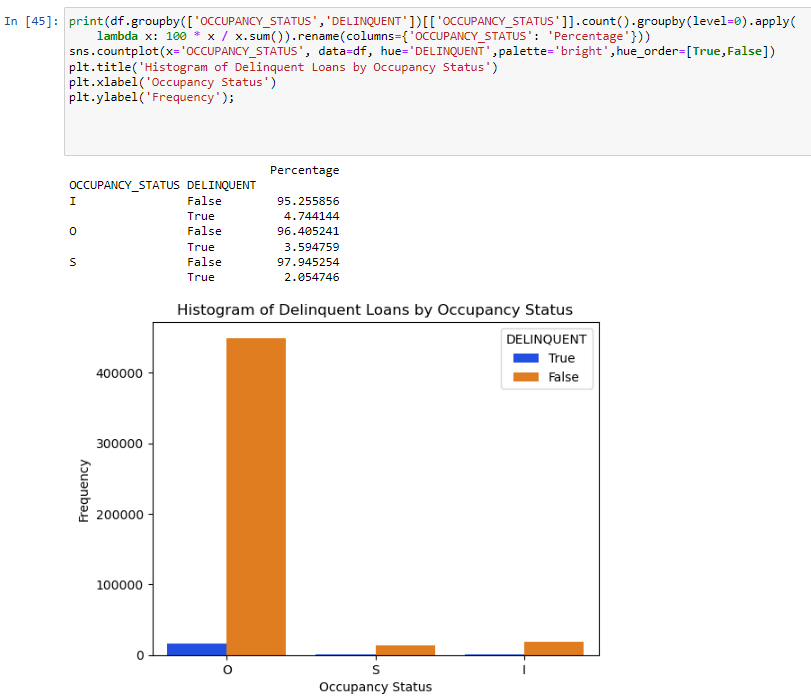
OCCUPANCY STATUS
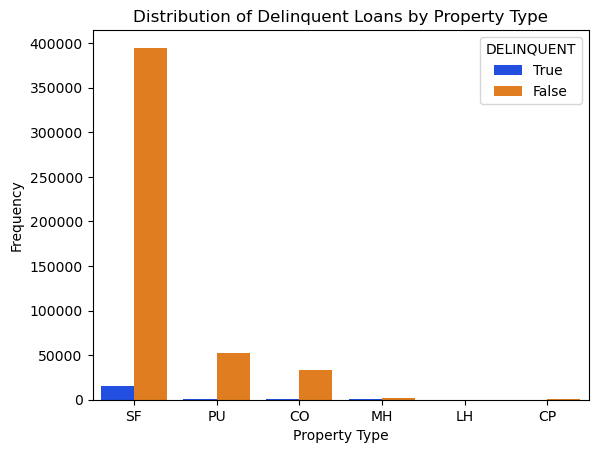
Property Type
Denotes whether the property type secured by the mortgage is a condominium, leasehold, planned unit development (PUD), cooperative share, manufactured home, or Single-Family home.
- CO = Condo
- PU = PUD
- MH = Manufactured
Housing
- SF = Single-Family
- CP = Co-op
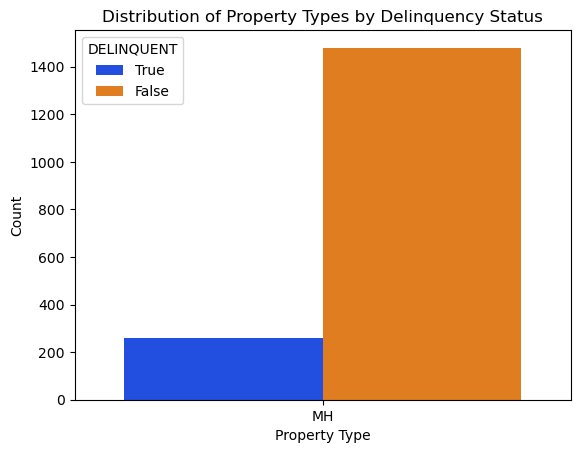
Majority of Property are single family homes but Manufactured Homes show a significant portion of delinquent
Please see chart below without SF for a clearer picture.
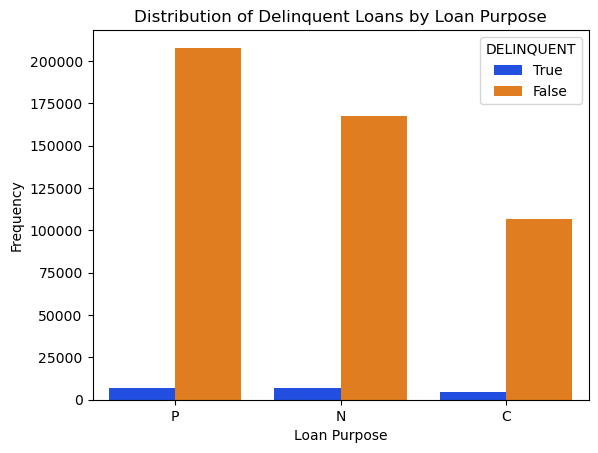
LOAN PURPOSE
Indicates whether the mortgage loan is a Cashout Refinance mortgage, No Cash-out Refinance mortgage, or a Purchase mortgage.
- Cash-out Refinance mortgage loan is a mortgage loan in which the use of the loan amount is not limited to specific purposes.
- No Cash-out Refinance mortgage loan is a mortgage loan in which the loan amount is limited to the following uses:
- Pay off the first mortgage, regardless of its age
- Pay off any junior liens secured by the mortgaged property, that were used in their entirety to acquire the subject property
- Pay related closing costs, financing costs and prepaid items.
- Purchase mortgage: the borrower is seeking to obtain financing for a new home purchase, and the mortgage is secured by the property being purchased
- Cash out mortgages are the riskier and they have bigger proportion delinquent customers
It is Important to drop Prepaid and label Delinquency as it creates dataleakage

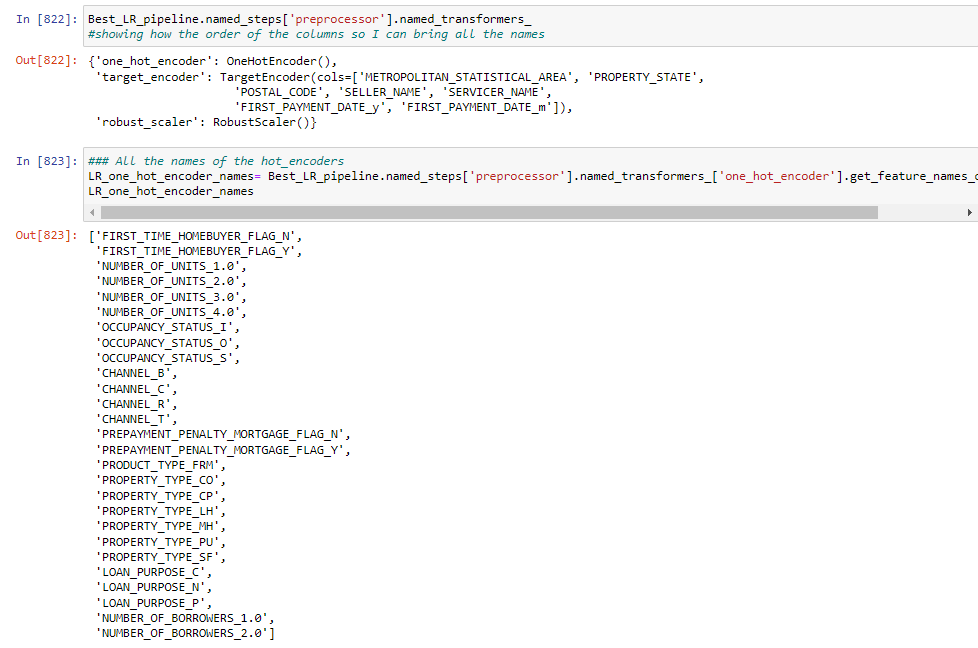
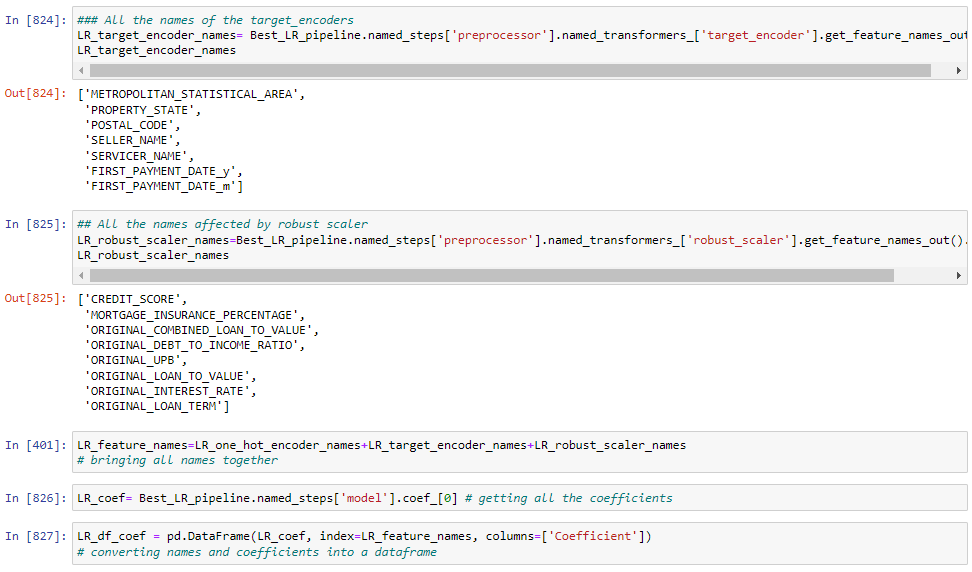
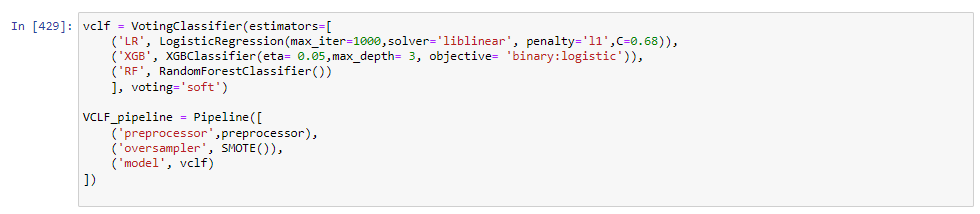
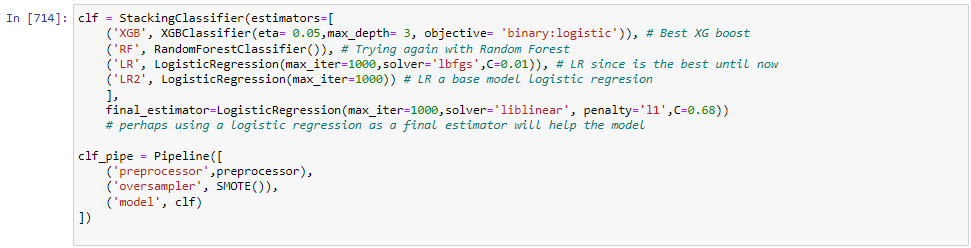
All models used the same preprocessor as in the LR model.
XGB boost did not perform well in recall.

RF did not perform well in recall.


Better than the standalone XGbooster and Random Tree but not close to LR in recall

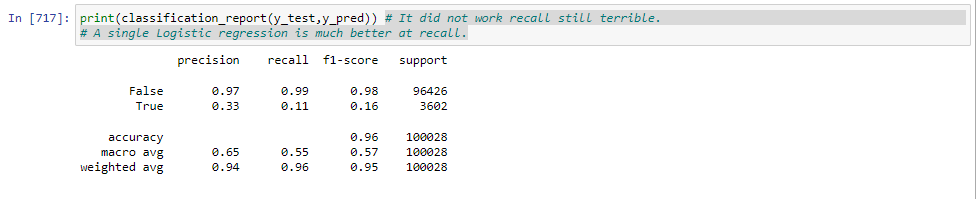
A single Logistic regression is much better at recall.
LIME - Local Explanations
Customer 158431 was predicted as delinquent when it was not.
- We can see that the Servicer Name, Property Type Cooperative, the credit core and the Occupancy Status as secondary are the main features moving this client to Delinquent according to the model.
- Not being par of Channel correspondent or broker, having 2 borrowers on the loan and that the loan purpose is to purchase a home all help the customer to bein a non-delinquent but not enough just 20%

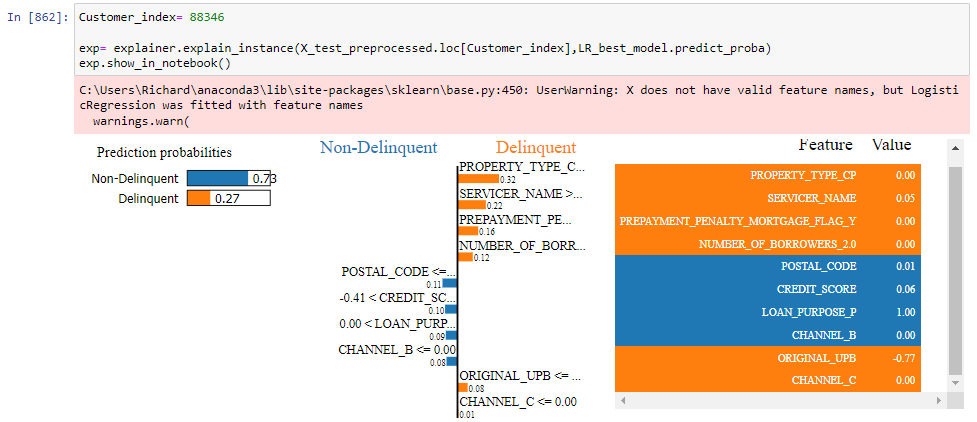
Customer 88346 was predicted as non-delinquent when it was delinquent.
- This false-negative is probably more important than the previous false-positive as this customer will default when the model says that it wouldn't.
- With a credit score of 724 which is very good is really hard to predict that this customer would default.
- Also it seems that the postal code is also full of non_delinquents so again the model struggles to identify it as Non Delinquent.
Creating Function to create all the preprocess steps and Oversamples outside a pipeline
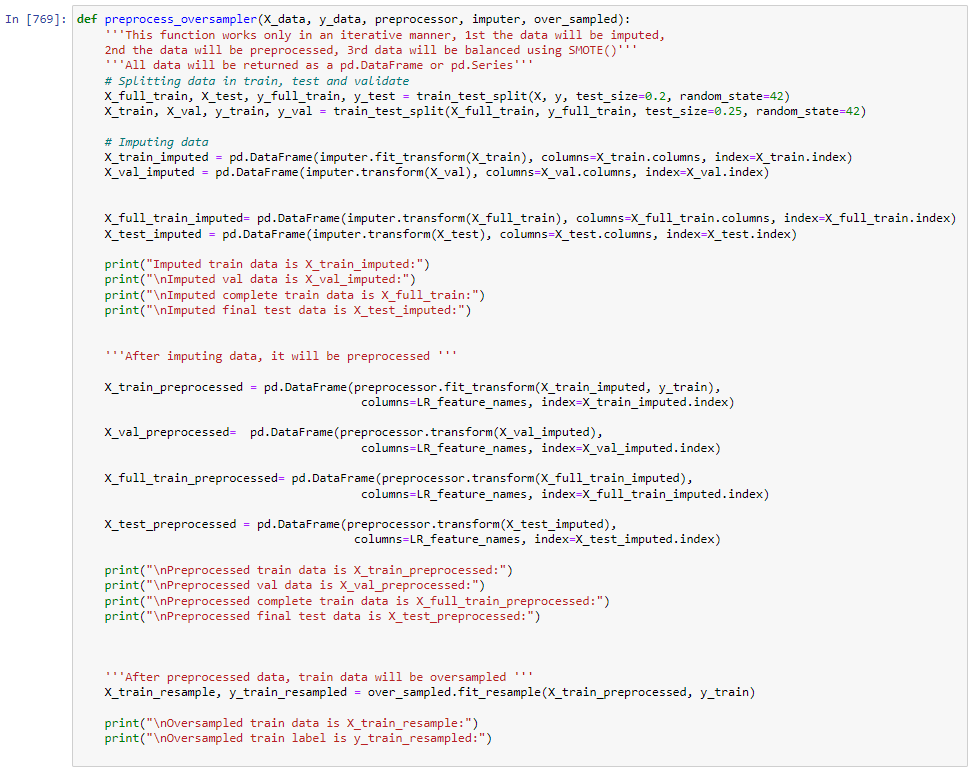
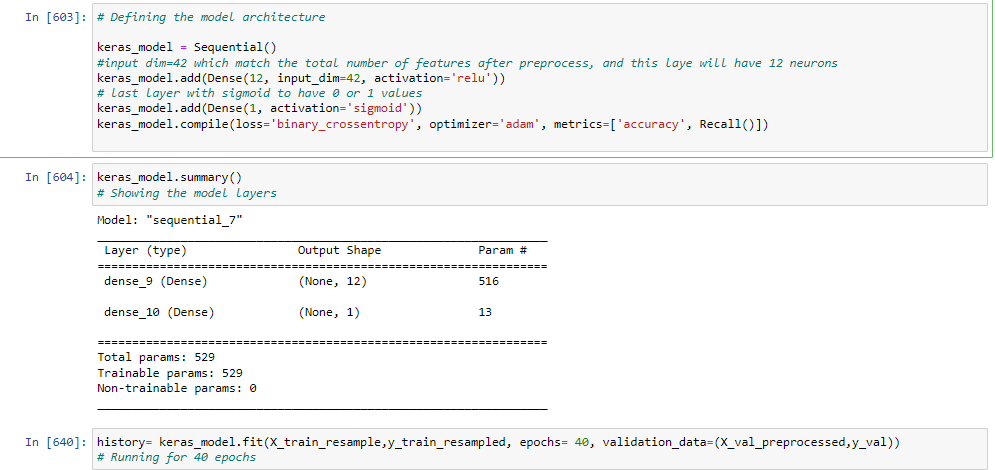
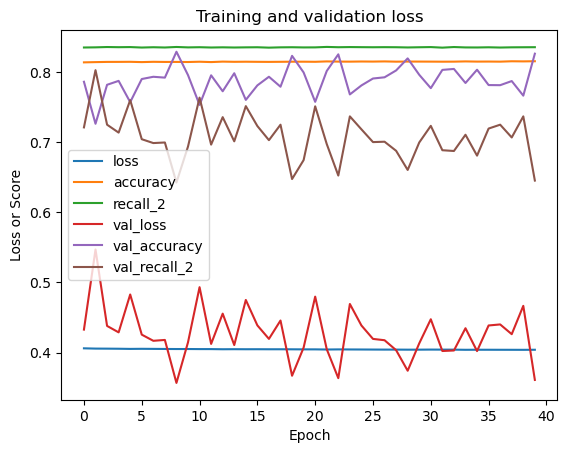
More experimentation with the number of layers and neurons is available on the notebook. Eventhough it has a recall value of around 70%, the logistic regression model is easier to interpret and run.
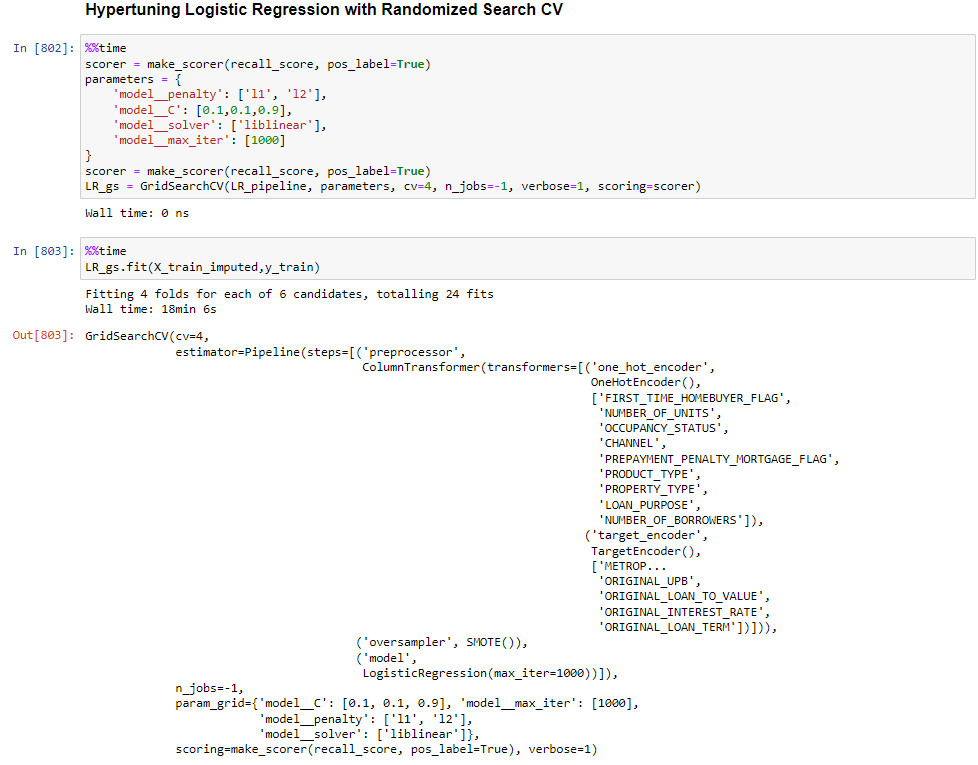
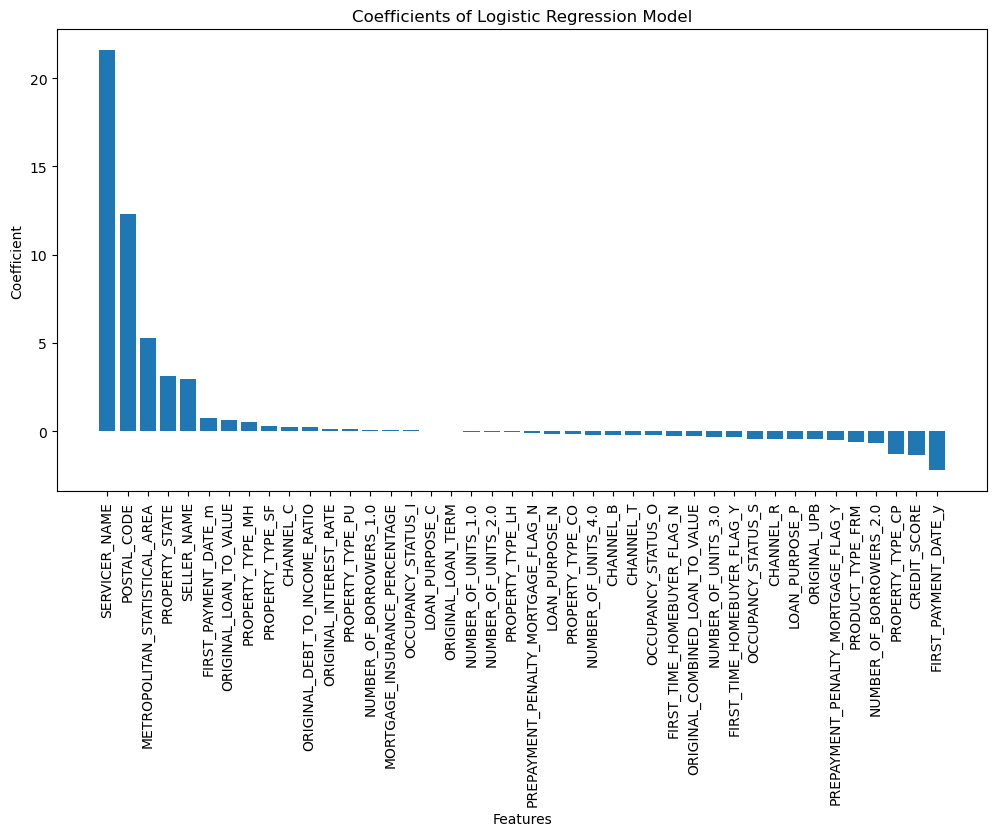
The best model is a Logistic Regression with the following parameters:
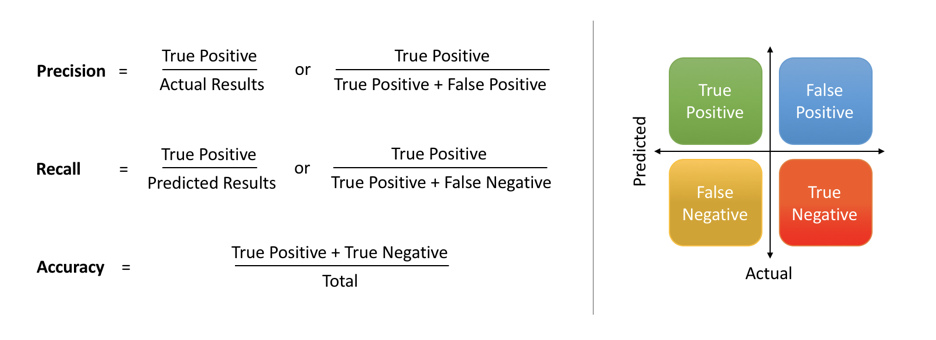
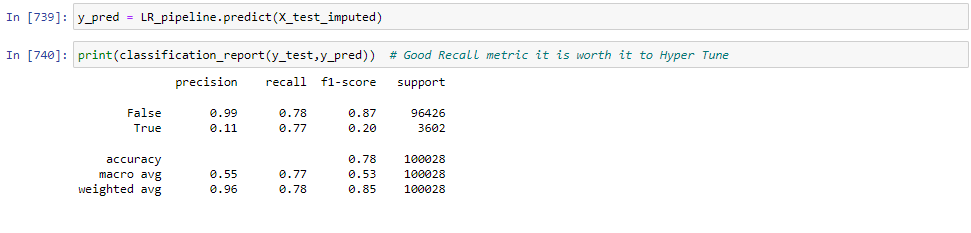
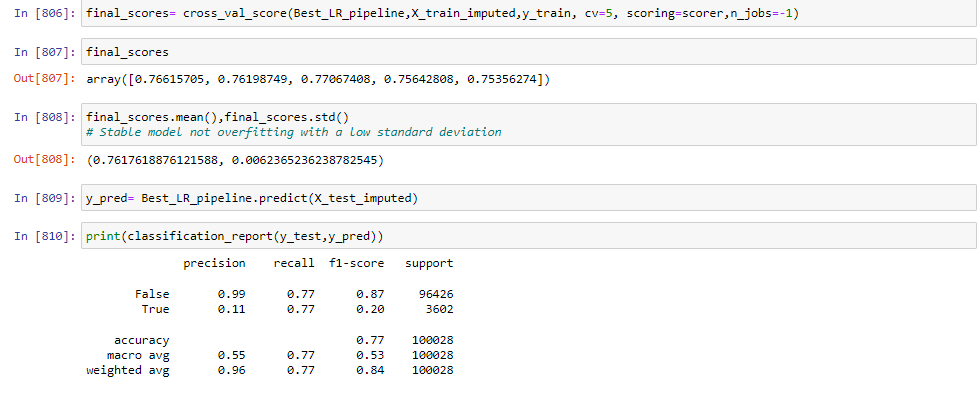
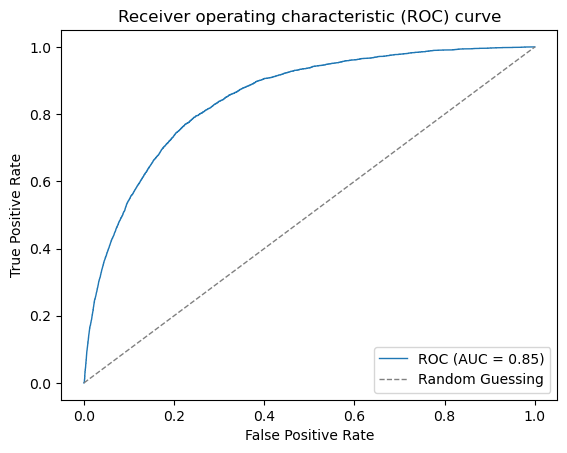
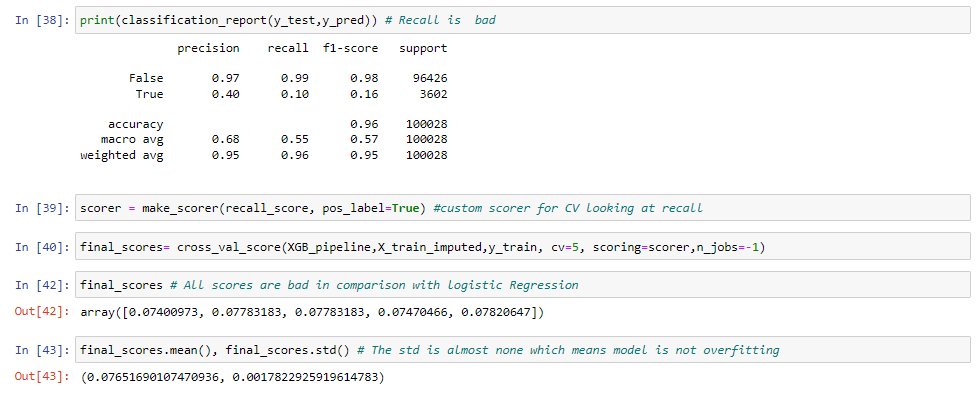
This model will correctly identify 76% of all positive cases (i.e., the cases where the loan is actually delinquent). In other words, the model has the ability to avoid false negatives, or cases where the model incorrectly predicts that a loan is not delinquent when it actually is.
However, it has a precision score of 0.11 means that out of all the loans predicted as delinquent by the model, only 11% were actually delinquent. In other words, the model is not very precise in identifying delinquent loans and is likely to generate a lot of false positives (i.e., cases where the model predicts that a loan is delinquent when it actually is not).
One of the advantages of using a logistic regression model is its interpretability, which makes it compliant with the Fair Housing Act. The Act prohibits discrimination in the sale, rental, and financing of housing based on certain protected characteristics, such as race, color, national origin, religion, sex, familial status, and disability. Therefore, it is important for lenders to ensure that their models do not discriminate against any protected groups. Logistic regression models are easier to interpret than other models like neural networks, which can be seen as "black boxes" due to their complex architecture. By using a logistic regression model, lenders can better understand which features are driving the model's predictions and ensure that they are not inadvertently discriminating against any protected groups.