
K-Means Text Clustering project.
The objective of this project was to perform text clustering on the popular dataset, "Twenty News Group," obtained from https://scikit-learn.org/0.19/datasets/twenty_newsgroups.html
Text clustering is a subfield of unsupervisedmachine learning that involves grouping together similar textual data into clusters
In github you can find the code for this project here.
And my complete portfolio here.
This technique has several significant applications, here are some popular ones:
- News Aggregation: Groups similar news stories together for easy discovery and follow-up.
- Social Media Analysis: Clusters similar social media posts or comments for trend monitoring and identifying related content.
- Customer Feedback Analysis: Categorizes similar customer reviews or feedback for identifying common problems or praise points
- Email Filtering: Helps classify similar emails, streamlining user inboxes.
- Search Engine Optimization: Clusters similar search queries together, providing insights for content optimization.
The function tokenize_and_lemmatize will do the following:
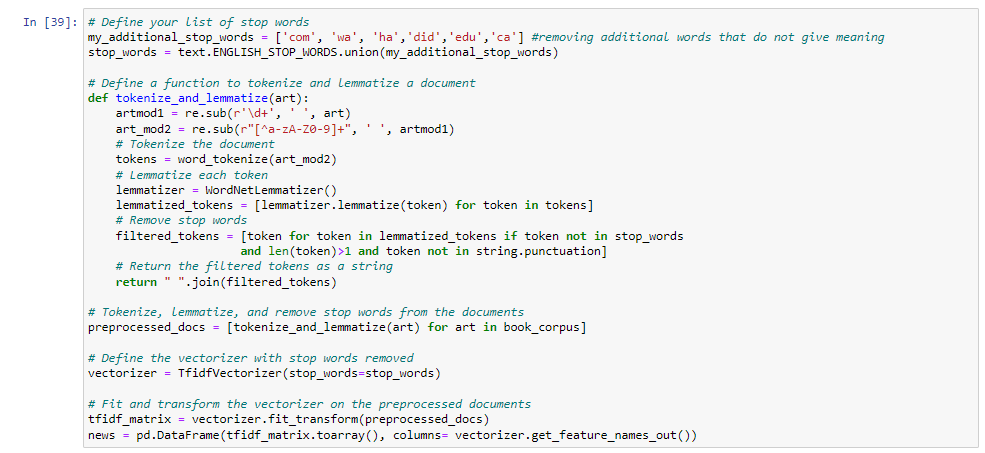
Stop Words Definition: A list of stop words (common words that add little value to text analysis) is defined, with custom stop words being added to the standard English stop words.
Tokenization and Lemmatization Function: The tokenize_and_lemmatize function preprocesses text by:
Preprocessing Documents: The tokenize_and_lemmatize function is applied to each document in book_corpus, resulting in a list of preprocessed documents.
Vectorization: A TfidfVectorizer object is created, removing the defined stop words. It transforms the preprocessed documents into a TF-IDF matrix. TF-IDF (term frequency-inverse document frequency) is a statistic that reflects how important a word is to a document in a collection or corpus.
Data Frame Creation: The TF-IDF matrix is converted into a pandas DataFrame where each row corresponds to a document, and each column represents a unique word in the corpus. The cell values reflect the TF-IDF score for each word in each document. This results in a numerical representation of the text data, which can be used for further analysis.
A brief explanation of what each step is doing:
Tokenization: This is the process of breaking down text into individual words or terms, called tokens. For example, tokenizing the sentence "I love ice cream" results in the tokens "I", "love", "ice", and "cream". It's one of the first steps in many natural language processing (NLP) tasks.
Lemmatization: This is the process of reducing words to their base or dictionary form, known as the lemma. For example, the words "running", "runs", and "ran" are all forms of the word "run", so "run" would be the lemma of all these words. Lemmatization is used to avoid treating different forms of the same word as different words during text analysis.
TfidfVectorizer: This is a class provided by the scikit-learn library in Python that converts a collection of raw documents to a matrix of TF-IDF features. TF-IDF stands for Term Frequency-Inverse Document Frequency, a numerical statistic that reflects how important a word is to a document in a collection or corpus. It's often used in information retrieval and text mining. The importance increases proportionally to the number of times a word appears in the document but is offset by the frequency of the word in the corpus, which helps to adjust for the fact that some words appear more frequently in general.
KMeans
- After using TF-IDF vectorizer, the transformation results in a large sparse matrix (in our case 4617 features) Clustering with high-dimensional data can be difficult, so dimension reduction is necessary.
- The model must find a balance between Total Variance explained and a reasonable clustering number.
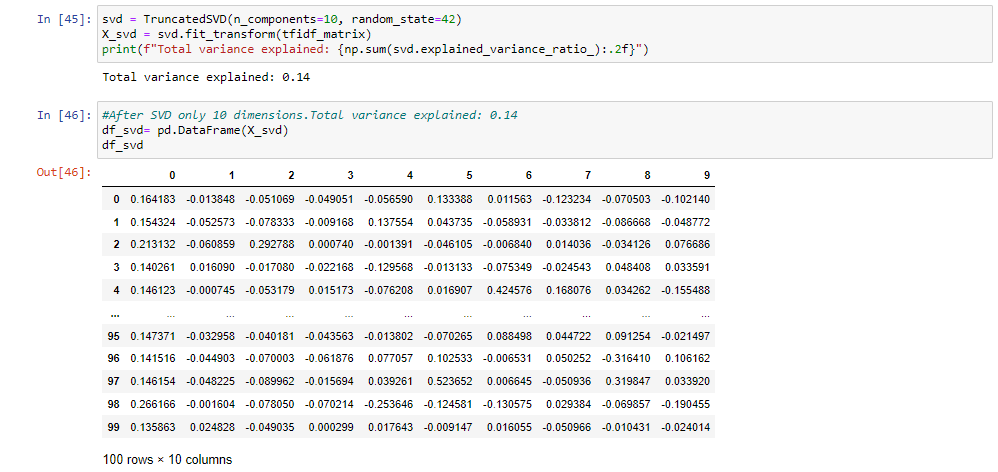
- We decided to choose 10, it has the disadvantage of only explaining 14% of variance, but is a good selection on the elbow curve.Also, it is a reasonable clustering number since our dataset contained 100 news-articles now we are trying to separate them into 10 topics.
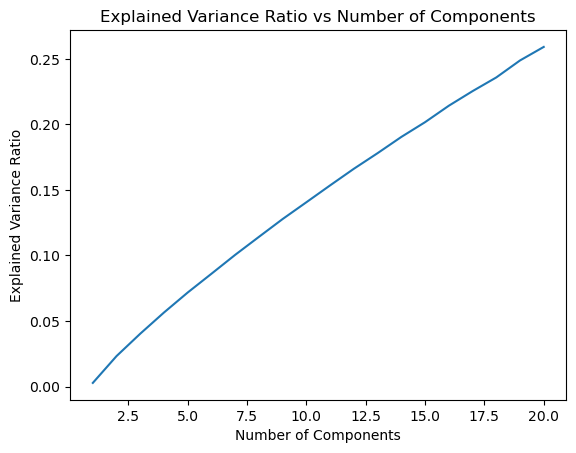
After reducing dimensionality, now is time to select the number of Clusters. By reviewing the elbow curve, we can see that anything around 10 to 15 seems to be the sweet spot between reducing the Squared error and how many cluster to have.
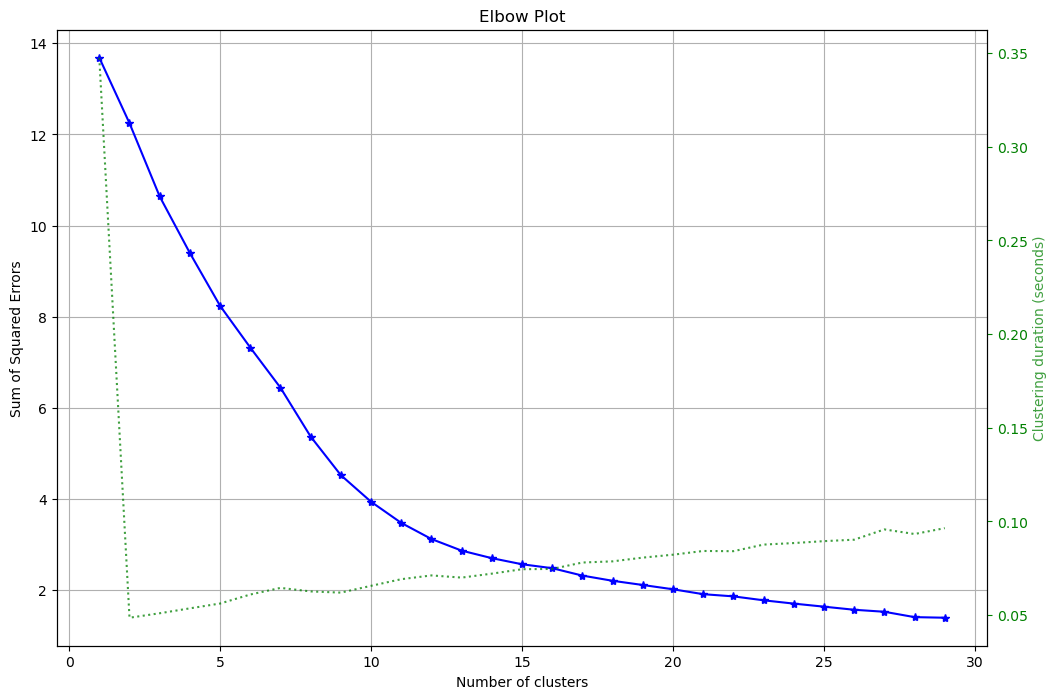
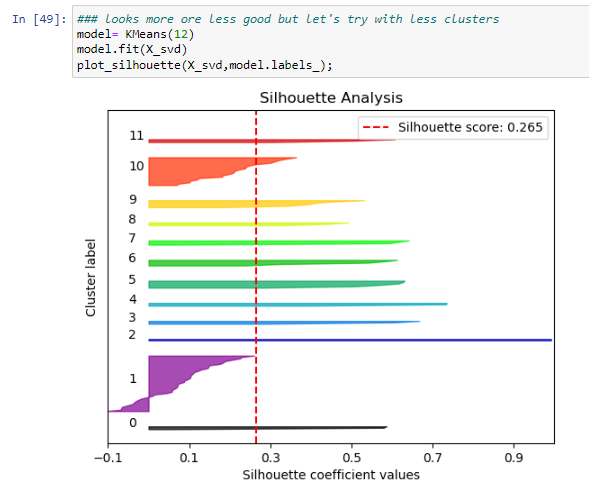
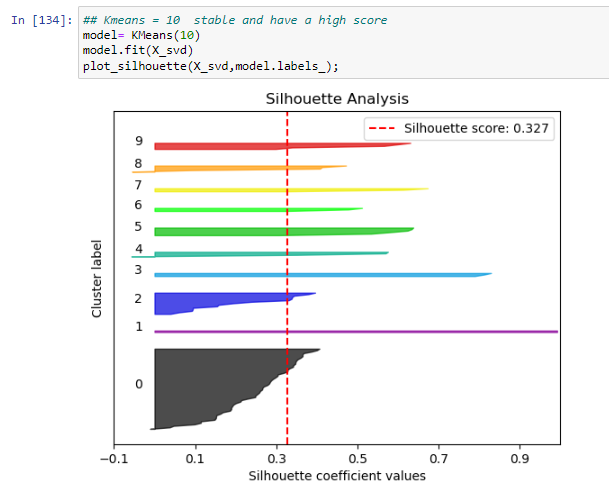
It seems like 10 has the highest Silhoutte score and it is between the range of optimal values in the elbow plot, so it is the best one.
To review if the clusters have a logical topic. I created wordclouds to review each cluster

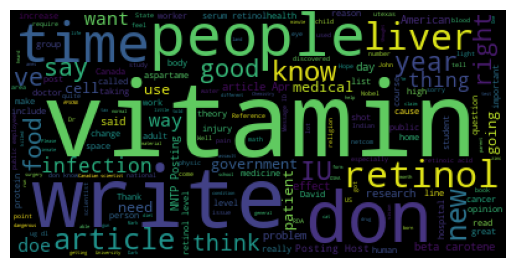
Not all cluster are as well defined as the ones shown and we can see that in dome cases some words do not seem to be related, but it is a good base to iterate and find a better solution.
K-means clustering requires striking a balance between maximizing the total variance explained through dimension reduction and maintaining a reasonable number of clusters that align with the end goal - in this case, the desired number of topics.
Although K-means is a popular choice, other machine learning algorithms might perform better when it comes to clustering text data. Hierarchical Clustering, for example, is often preferred because it allows the user to select not just the final cluster, but also intermediate clusters by cutting the dendrogram at a specific level.
In this exercise, we have opted for TF-IDF vectorization with n_grams set to 1. However, it's possible to use a broader range or a larger fixed number to identify groups of words that could carry more meaning. Other vectorization techniques, such as Word Embeddings – specifically Word2Vec and others, can also be employed as alternatives.